Softmax를 이용한 fashion MNIST 데이터세트로 이미지 분류
* 딥러닝이 기존의 프로그래밍 메서드로는 불가능했던 문제를 어떻게 해결할 수 있는지 이해
* Fashion MNIST 옷 이미지 데이터세트에 대해 알아보기
* [Keras API](https://keras.io/)를 사용하여 fashion MNIST 데이터세트를 로드하고 트레이닝을 위해 준비
* 단순한 뉴럴 네트워크를 구축하여 이미지 분류 수행
* 준비된 fashion MNIST 데이터세트를 사용하여 뉴럴 네트워크 트레이닝
* 트레이닝된 뉴럴 네트워크의 성능 관찰
트레이닝 및 검증을 위한 데이터와 레이블
fashion_MNIST 데이터세트는 트레이닝과 검증을 위한 이미지데이터와 레이블을 가지고 있습니다.
따라서 다음과 같은 4개의 데이터 세그먼트가 필요합니다.
1. `x_train` : 뉴럴네트워크를 트레이닝하는데 사용되는 이미지
2. `y_train` : `x_train`에 대한 이미지 레이블
3. `x_test` : 예측(predict)을 위한 이미지
4. `y_test` : `x_test`에 대한 이미지 레이블
데이터 로딩
from tensorflow.keras.datasets import fashion_mnist
import numpy as np
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
fashion_MNIST 데이터 속성 알아보기
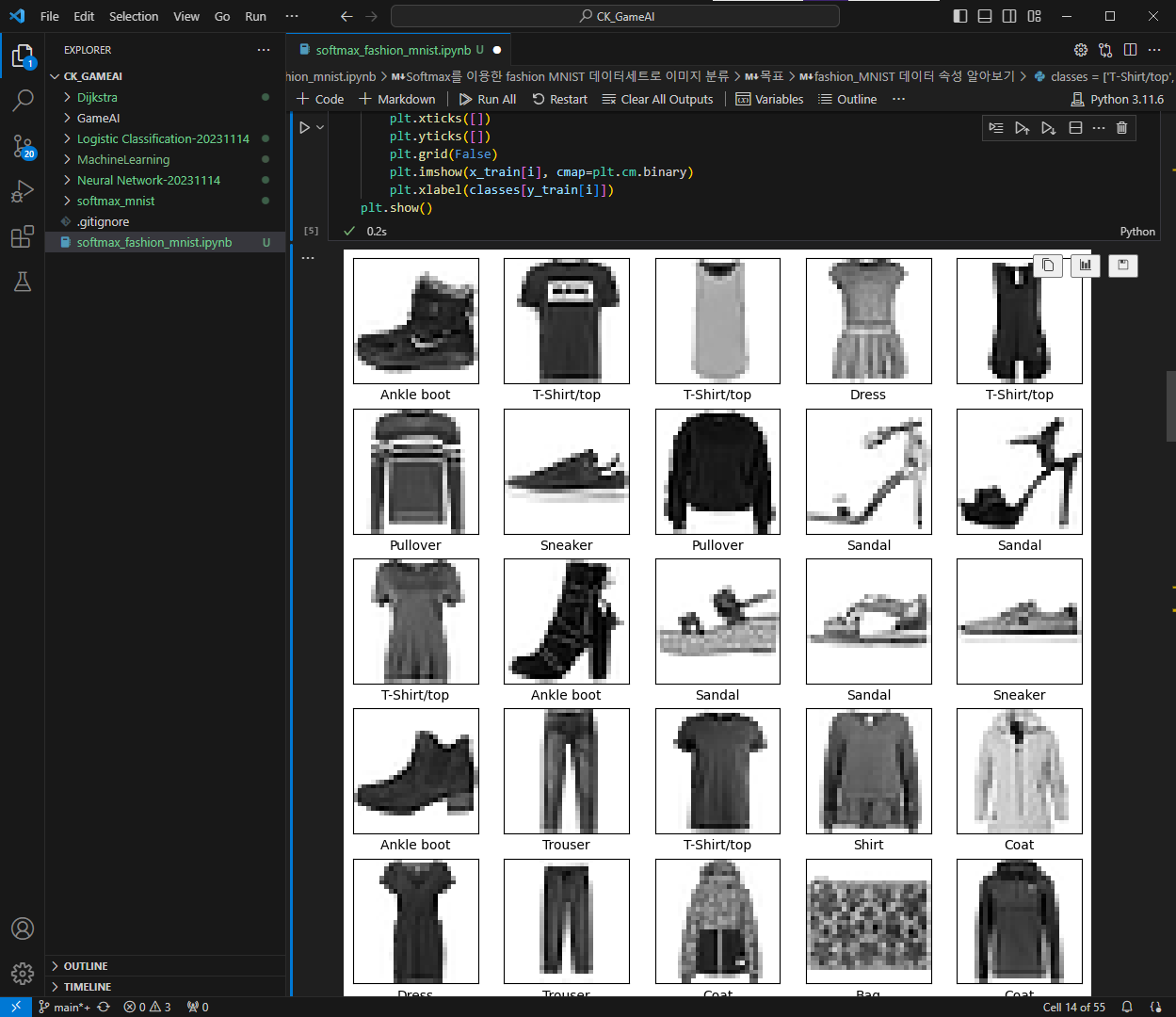
위에서 언급했던 것처럼 `fashion_MNIST` 데이터세트에는 다양한 옷으로 구성된 70,000개의 회색조 이미지가 포함되어 있습니다.
트레이닝(학습)을 위한 데이터 60,000개, 검증을 위한 데이터 10,000로 구성되어 있으며, 각 이미지는 28*28 픽셀의 2D 이미지입니다.
print("x_train : ", x_train.shape, "data type : ", x_train.dtype)
print("x_test : ", x_test.shape, "data type : ", x_test.dtype)
print(np.unique(y_train, return_counts=True))
또한, 28*28 이미지의 각 픽셀들의 값은 8비트 정수로 되어 있습니다.
즉, 0 ~ 255까지의 숫자로 되어 있습니다. 이는 각 픽셀의 회색조 값에 해당됩니다.
0은 검은색, 255는 흰색, 나머지 값들은 0~255 사이의 값에 해당됩니다.
print("x_train min val : ", x_train.min())
print("x_train max val : ", x_train.max())
x_train[0]
import matplotlib.pyplot as plt
print("y_train[0] : ", y_train[0])
img = x_train[0]
#plt.imshow(img, cmap='gray')
plt.imshow(img)

CNN (Convolution Neural Network, 합성곱신경망)
고양이의 시선에 따라 뇌에서 자극 받는 위치가 모두 다르다는 점을 착안
이미지 전체를 작은 단위로 쪼개어 각 부분을 분석하는 것이 핵심이다.
- 전반부 : 컨볼루션 연산을 수행하여 특징 추출
- 후반부 : 특징을 이용하여 분류
시각적 이미지를 분석하는데 주로 사용되는 딥러닝
영상분류, 문자 인식 등 인식문제에 높은 성능을 보여 많이 사용되고 있다.
CNN 구조
입력 > 합성곱 > Max Pooling > 합성곱 > 드롭아웃 > Max Pooling > 합성곱 > Max Pooling > 밀집 > 밀집 > 출력
합성곱층(Convolutional layer)과 풀링층(Pooling layer)으로 구성
합성곱층(Convolutional layer)
Softmax에서 숫자를 인식하는 머신러닝의 단점
3차원(가로, 세로, 채널)인 MNIST 데이터(28, 28, 1)를 1차웡느로 평탄화(Flat)한 입력층 사용
이로 인해 데이터 형상이 무시된다. 학습은 잘 되지만 검증 데이터에 대한 손실이 크게 나타남.
합성곱층은 입력 데이터의 형상을 유지
- 3차원 이미지를 그대로 입력층에서 입력받고, 출력도 3차원 데이터로 출력하여 다음 계층으로 전달.
- 주어진 데이터에 특정한 특징이 데이터에 있는지를 검출해 주는 함수
흐리게 하거나, 선명하게 하거나, 밝게 하거나, 어둡게 하는 데에도 합성곱을 사용한다.
필터를 거치면 원래의 사이즈보다 작아진다.
https://setosa.io/ev/image-kernels/
컨클루션 연산
- 커널(필터)로 표현되는 특징이 컨볼루션 연산이 수행되는 데이터 영역에 얼마나 강하게 존재하는지 평가
특징 지도 (feature map)
- 컨폴루션 필터의 적용 결과로 만들어지는 2차원 행렬
특정지도의 원소 값 : 커볼루션 필터에 표현된 특징을 대응되는 위치에 포함하고 있는 정도
k개의 필터를 적용하면 k개의 2차원 특징지도 생성
풀링충(Pooling layer)
윈도우의 모든 값을 살펴보고 단순한 통계 연산을 수행하는 방법
- Max Pooling (최대 풀링) : 윈도우 가장 큰 값을 취하고 나머지는 버림
- Average Pooling (평균 풀링) : 해당 영역의 평균값을 계산한다.
CNN 구조
특징 추출을 위한 컨볼루션 부분 (반복)
- 컨볼루션 연산을 하는 컨볼루션 층
- ReLU 연산을 하는 ReLU > 활성화 함수
- 풀링 연산
추출된 특징을 사용하며 분류 또는 회귀를 수행하는 다층 퍼셉트론 부분
- 전방향 전체 연결된 Fully Connected 층 반복
- 분류의 경우 마지막 층에 Softmax 연산 추가
Image Kernels explained visually
An image kernel is a small matrix used to apply effects like the ones you might find in Photoshop or Gimp, such as blurring, sharpening, outlining or embossing. They're also used in machine learning for 'feature extraction', a technique for determining the
setosa.io
'대학생활 > 수업' 카테고리의 다른 글
| 레벨디자인심화 12주차 - 던전 시나리오 (0) | 2023.11.30 |
|---|---|
| 리얼타임엔진 13주차 - UEFN 모델링 (0) | 2023.11.28 |
| 게임밸런스및시뮬레이션 12주차 - 가챠 뽑기 시뮬레이터 만들기 (0) | 2023.11.27 |
| 게임그래픽프로그래밍심화 12주차 (0) | 2023.11.27 |
| 게임배경음악과효과음 10주차 - 숨소리, 공포게임 실습 (0) | 2023.11.23 |

